Updated to RealVisXLTurbo. Image generations ~10 seconds. Uses GPT-4 Visions to generate prompts for images and SDXL with Controlnet for image generation.
Well, not exactly again – The original image is passed to GPT4 vision along with the article title and the image’s description, so it’s attempting to be contextual in its prompts and contextual to the shapes in the original image.
Ah sorry, I did not realize you were the author, I would have been less brutal. Then let me rephrase my criticism: I think it is unproductive to show reconstruction of statues or painting of archaeological interest. Maybe showcase it more on enhancement of black and ,white pictures or sci fi illustration ?


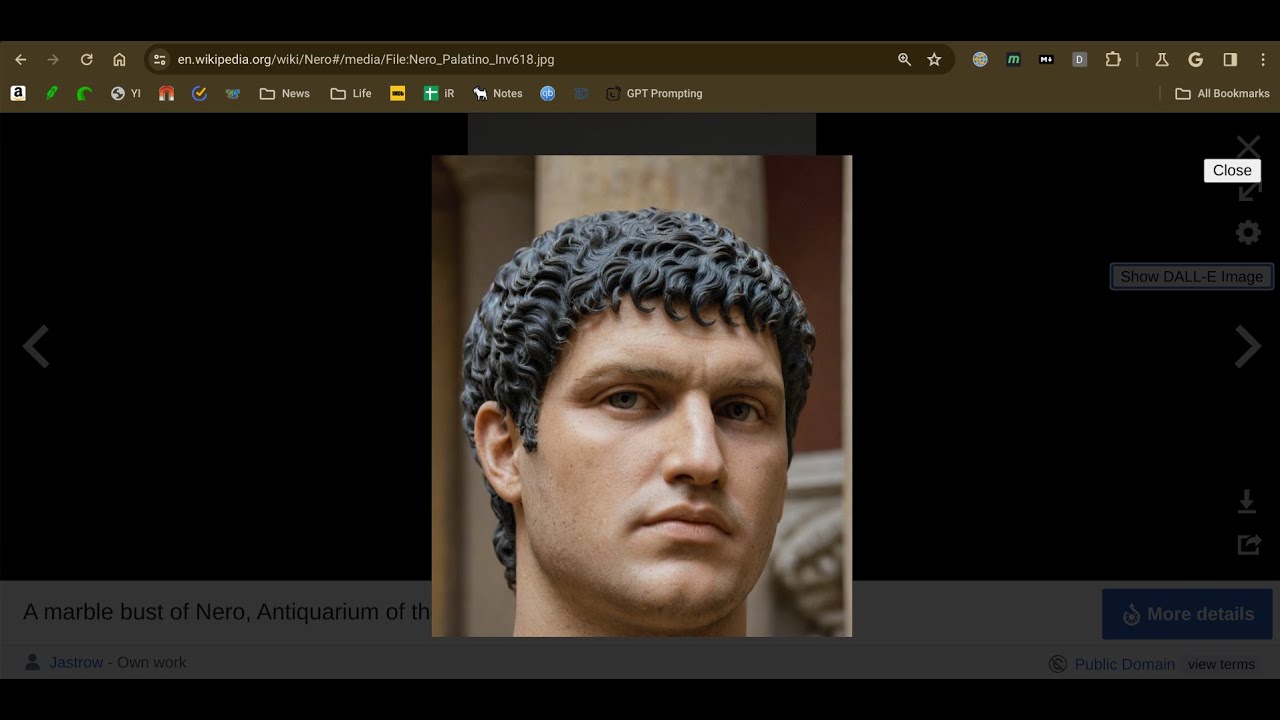
Well, not exactly again – The original image is passed to GPT4 vision along with the article title and the image’s description, so it’s attempting to be contextual in its prompts and contextual to the shapes in the original image.
And it fails.
I am pleased with it and its potential, especially for a v1. It’s OK that you don’t feel the same way.
Ah sorry, I did not realize you were the author, I would have been less brutal. Then let me rephrase my criticism: I think it is unproductive to show reconstruction of statues or painting of archaeological interest. Maybe showcase it more on enhancement of black and ,white pictures or sci fi illustration ?
all good thanks for the feedback! This will probably end up being the foundation for my weeb targeted saas app cash grab :P
Really fun tech project and supabase.com I’ve fallen in love with I think – best dev experience ever maybe